Comment:
Chris
Summary:
The paper introduced Tahuti, a geometrical sketch recognition system for UML diagram. The system is dual-view sketch recogniton environment, which based on a multi-layer recognition framework which recognizes multi-stroke objets by their geometrical properties allowing users the freedom to draw naturally as they would on paper. The system can provide two views, interpreted version of stroks and original strokes. Users can choose to switch between them at any time. And users can draw and edit while viewing either their original strokes or the interpreted version of their strokes engendering user-autonomy in sketching. The result shows that uers preferred Tahuti to a paint programs and to Rational Ross.
Discussion:
The system looks nice. I actually watched the demo from youtube about this system. It works pretty good for editing UML diagram, user can drag and move the class components to whevere they want. The system give much freedom for people to draw. And the beautiful idea here is to encourage people to switch between different views. In all, nice system which deleveoped by my advisor!
Tuesday, December 14, 2010
Reading #29: Scratch Input Creating Large, Inexpensive, Unpowered and Mobile Finger Input Surfaces (Harrison)
Comment:
Chris
Summary:
The paper introduces a acoustic-based recognier that relies on the unique sound produced when a fingernail is dragged over the surface of a textured material such as wood, fabric,or wall paint. The recognizer they made here can recognize 6 different basic shapes by obtaining about 90% accuracy with less than five minutes of training and on wide variety of surfaces.For recognition, they actually use the amplitude of waveform and figure out the shape of waveform like traiangle, rectangle, and so on. The other contribution of this paper is to introduce several example applications that can use this technology, mainly for the mobile applications.
Discussion:
Awesome idea! They used sketching sound source, which can be very useful for sketch recognition. In fact, our projects idea come from this this paper. As far as I know, this
is the first paper that show the sketching sound can be used to variety of applications in real life,especailly for the mobile devices. This work could be extend to more complicate cases, which I am trying to do.
Reading #28: iCanDraw? – Using Sketch Recognition and Corrective Feedback to Assist a User in Drawing Human Faces (Dixon)
Comment:
Chris
Summary:
This paper shows the first system for using computer-aided instruction to assits a student in learning to draw human faces. This system uses face and sketch recognition to understand the reference photograph of a human model and a user's drawing of it. When users drawing, the system can give feedback step by step once user require it. Actually, there is matching between template image and user drawing. Face recogniton algorithm is applied to template image and get feature set for this template image. And by using these features, the system can give feedback to users at real time.
Comment:
This is one of paper that written by our lab. However, I didn't use the system before. But anyway, the idea behind this paper is excellent. Giving feedback at real time is one important advantage for tutoring/educational system.
Reading #27: K-sketch: A 'Kinetic' Sketch Pad for Novice Animators (Davis)
Comment:
Chris
Summary:
In this paper, they introduced the K-Sketch, a general purpose, informal,2D animation sketching system. At first, they do the field studies investigating the needs of animators and would-be animators helped us collect a library of usage scenarios for their tool. Then they design the set of operations for animation as well as some optimazation techniques they used in K-Sketch. Experiment shows that K-Sketch when comparing to formal animation tool(ppt), participants worked three times faster, needed half the learning time, and had significantly lower cognitive load with K-Sketch.
Discussion:
In fact, I am thinking about building such kind of system, and K-Sketch is what I am expecting. For most of novice users, using flash software for animation is not easy task, user need such system to fasten the process of making animation. After reading this paper, I cannot wait using that system to see how is it working!!
Reading #26: Picturephone: A Game for Sketch Data Capture (Johnson)
Comment:
Chris
Summary:
In this paper, the author introduce the PicturePhone, a game for sketch data capture. This game needs three participants, the first participant is required to draw sketch according to the discritpion. The game works as follows: Player A is given a text description, and they must make a drawing that captures that description as accurately as possible. Player B receives the drawing and endeavors to describe it. Player C is given Player B's description and draws it. An unrelated player D is asked to judge how closely Player A and C's drawing match, which assigns a score to players A,B and C. The purpose of this system is to collect sketch data for researchers.
Discussion:
This is a smart idea. The data collection is very important for sketch recogntion research. And data collection itself is not easy for researchers. This software gives us a new way for collecting data, while encourage people to participate in data collection. But the problem is, at least in my opinion, I will not be happy to play such game, which seems boring to me and waste of time, and I don't care about how much score I get...
Chris
Summary:
In this paper, the author introduce the PicturePhone, a game for sketch data capture. This game needs three participants, the first participant is required to draw sketch according to the discritpion. The game works as follows: Player A is given a text description, and they must make a drawing that captures that description as accurately as possible. Player B receives the drawing and endeavors to describe it. Player C is given Player B's description and draws it. An unrelated player D is asked to judge how closely Player A and C's drawing match, which assigns a score to players A,B and C. The purpose of this system is to collect sketch data for researchers.
Discussion:
This is a smart idea. The data collection is very important for sketch recogntion research. And data collection itself is not easy for researchers. This software gives us a new way for collecting data, while encourage people to participate in data collection. But the problem is, at least in my opinion, I will not be happy to play such game, which seems boring to me and waste of time, and I don't care about how much score I get...
eading #25: A Descriptor for Large Scale Image Retrieval Based on Sketched Feature Lines (Eitz)
Comment:
Chris
Summary:
The paper addresses the problem of large scale sketch based image retrieval. The main contribution is a sketch-based query system for image database containing millions of images.For the traditional search system, users can only provides word for searching. For searching for images, they also have to provide word to describe the image, which seems very hard in some cases. However, people could remember how the image looks like, and they can tell you by sketching them on the paper. The system is doing that! Using sketched image to search for real images in the image database. The result show that their system is superior to a variant of the MPEG-7 edge histogram descriptor in a quantitative evaluation.
Discussion:
Wow! Awesome! This is my favorite system that I've seen before. As far as I know, this likely be the future search engine. Combine sketch and word to search for image is very cool thing and can give much accurate images that people want to retrieve. And it is better to let the system can learn from the people's action like selecting picuture.I am very excited to see this system.
Reading #24: Games for Sketch Data Collection (Johnson)
Comment:
Chris
Summary:
This paper is very similar with what I read just before. The paper introduces several systems which aim to collect sketching data for research purpose. These data can be shared by researchers on the web. In this paper, they showed two system, Picturephone and Stellasketch two sketching games for collecting data about how people make and describe hand-made drawings. The first system is already described in the previous paper in detail. Stellasketch is a synchronous, multi-player sketching game similar to the parlor game Pictionary. One player is asked to make a drawing based on a secret clue. The other palyers see the drawing unfold as it is made and privately label the drawing. While Picturephone's descriptions are meant to be used to recreate a drawing.
Comment:
This paper seems more detail than the previous paper. As said in previous discussion section, I pretty much the idea behind this author. They make the collecting sketching data, a boring task for participant, more interesting, in addition, this might encourage some people to participant these games. However, we might doubt about the correctness of these sketch data.
Reading #23: InkSeine: In Situ Search for Active Note Taking (Hinckley)
Comment:
Chris
Summary:
The paper introduce the fluid interface that encourage users to engage in active note taking. InkSeine is a Tablet PC application that supports active note taking by coupling a pen-and-ink interface with an in situ search facility that flows directly from a user’s ink notes InkSeine integrates four key concepts: it leverages preexisting ink to initiate a search; it provides tight coupling of search queries with application content; it persists search queries as first class objects that can be commingled with ink notes; and it enables a quick and flexible workflow where the user may freely interleave inking, searching, and gathering content. InkSeine offers these capabilities in an interface that is tailored to the unique demands of pen input, and that maintains the primacy of inking above all other tasks.The author also do the user studies so that maximize usability and focus on potential user scenarios.
Discussion:
Seems good,but I am not sure that I like the system. I guess that the system might not have fast speed.
Chris
Summary:
The paper introduce the fluid interface that encourage users to engage in active note taking. InkSeine is a Tablet PC application that supports active note taking by coupling a pen-and-ink interface with an in situ search facility that flows directly from a user’s ink notes InkSeine integrates four key concepts: it leverages preexisting ink to initiate a search; it provides tight coupling of search queries with application content; it persists search queries as first class objects that can be commingled with ink notes; and it enables a quick and flexible workflow where the user may freely interleave inking, searching, and gathering content. InkSeine offers these capabilities in an interface that is tailored to the unique demands of pen input, and that maintains the primacy of inking above all other tasks.The author also do the user studies so that maximize usability and focus on potential user scenarios.
Discussion:
Seems good,but I am not sure that I like the system. I guess that the system might not have fast speed.
Reading #22: Plushie: An Interactive Design System for Plush Toys (Mori)
Comment:
Chris
Summary:
The paper introduced the plushie, an interactive system that allows nonprofessional users to design their own original plush toys. The system provide different gestures for different editing behaviors. The system also provide feeback at real time that let people know how the 2D textured pieces looks like. The experiment results shows that the participants, which consists of kids, can draw flush toys without any difficulties and they also enjoy the system.
Discussion:
Honestly, I am not interested in this system, but in the HCI perspective, the system is very useful for aiding users to draw what they are hard to do before. The system seems more intesting for kids. I guess kids will be happy with the system and can draw very funny toys with the help of this system. In all, I am not so into the detail of system due to the fact that I am not interested in this system.
Reading #21: Teddy: A Sketching Interface for 3D Freeform Design (Igarashi)
Comment:
Chris
Summary:
The paper presents a sketching interface for quickly and easily designing freeform models from 2D sketch to 3D models. The user draws several 2D freeform strokes interactively on the screen and the system automatically constructs 3D polygonal surfaces.The system can supports several operations for uer to create 3D models, including the operation to construct a 3D polygonal surface from a 2D silhouette drawn by the user. The result shows that the system can be accomplished the task at real time. The reaming part of this paper describes the algorithm for implementing the system.
Discussion:
Cool Idea! In fact, building 3D objects is very hard problem for novice user, including me. The nice contribution of this paper is, to provide multiple operations to control the process of modeling objects, and see the 3D modeling in real time so that encourage the user to modify it real time as well. The work has great potential for animation task , as well as eduationg people to draw 3D simple objects. I like the paper and I hope I can use the system to produce some nice 3D pictures.
Reading #20: MathPad2: A System for the Creation and Exploration of Mathematical Sketches (LaViola)
Comment:
Chris
Summary:
In this paper, the author describes the MathPad, a math algebra editing system, aims to provide easy use for users. The user can wrote the math equation on the screen and the system can automatically recognize the equation and solve them. The author also developed several useful gestures to edit or command the math equation that already wrote, including delete, scribble, tap, and etc. Besides recognize and solve the foundamental math equations for us, the system can also handle the matrix, including adding, multiplication, reverse,etc. And the system can also plot the funcion in the screen by using simple gesture. In all, Mathpad is very nice, and the best algebra editing system among all the sketch-based math system.
Discussion:
In fact, I read the paper long time ago. The system is very beautiful, and most of all, it is not easy to design and implement all these functionalities in one system. There are many difficulties when designing such system. The individual character recogniton is the first problem we should conquer, which itself is very hard problem. If the character set is large, the recogniton for individual character becomes very hard. In order to recognize the whole formula, the system needs formula parser, however, the parser need to handle with many difficulties and ambiguities in the math equaiton, like lower case, upper case, and etc. In all, Mathpad is awsome, but I still doubt about its accuracy, it should be not high if user does not draw carefully.
Chris
Summary:
In this paper, the author describes the MathPad, a math algebra editing system, aims to provide easy use for users. The user can wrote the math equation on the screen and the system can automatically recognize the equation and solve them. The author also developed several useful gestures to edit or command the math equation that already wrote, including delete, scribble, tap, and etc. Besides recognize and solve the foundamental math equations for us, the system can also handle the matrix, including adding, multiplication, reverse,etc. And the system can also plot the funcion in the screen by using simple gesture. In all, Mathpad is very nice, and the best algebra editing system among all the sketch-based math system.
Discussion:
In fact, I read the paper long time ago. The system is very beautiful, and most of all, it is not easy to design and implement all these functionalities in one system. There are many difficulties when designing such system. The individual character recogniton is the first problem we should conquer, which itself is very hard problem. If the character set is large, the recogniton for individual character becomes very hard. In order to recognize the whole formula, the system needs formula parser, however, the parser need to handle with many difficulties and ambiguities in the math equaiton, like lower case, upper case, and etc. In all, Mathpad is awsome, but I still doubt about its accuracy, it should be not high if user does not draw carefully.
Reading #19: Diagram Structure Recognition by Bayesian Conditional Random Fields (Qi)
Comment:
Chris
Summary:
The paper uses bayesian conditional random fields to recognize sketched diagrams. Instead of recognize each element of digrams individually, they jointly analyzes all drawing elements in order to incorporate contextual cues. The classification uses the spatial and temporal information, and they have made a great assumption that classifying one object has impact one another object. The idea is very important when we utilizing the context informaiton into sketch recogniton. The result shows that their method can avoid overfitting problem and much better than maximum likehood and Maximum a posterior trained CRFs. The majority of this paper focused on mathematical detail of implementaiton.
Disccusion:
What a fantastic paper! The paper shows my initial idea about sketch recognition. I am always beliving that without context information of sketch, the recogniton is not feasible in most of cases, at least, does not obtain high accuracy. In order to maximize recognition accuracy, we must use the context information, also for the shape vs text task. They use baysian theory to incorpate this context information into their recogniton result. This is very very nice paper, and worth carefully reading it.
Chris
Summary:
The paper uses bayesian conditional random fields to recognize sketched diagrams. Instead of recognize each element of digrams individually, they jointly analyzes all drawing elements in order to incorporate contextual cues. The classification uses the spatial and temporal information, and they have made a great assumption that classifying one object has impact one another object. The idea is very important when we utilizing the context informaiton into sketch recogniton. The result shows that their method can avoid overfitting problem and much better than maximum likehood and Maximum a posterior trained CRFs. The majority of this paper focused on mathematical detail of implementaiton.
Disccusion:
What a fantastic paper! The paper shows my initial idea about sketch recognition. I am always beliving that without context information of sketch, the recogniton is not feasible in most of cases, at least, does not obtain high accuracy. In order to maximize recognition accuracy, we must use the context information, also for the shape vs text task. They use baysian theory to incorpate this context information into their recogniton result. This is very very nice paper, and worth carefully reading it.
Reading #18: Spatial Recognition and Grouping of Text and Graphics (Shilman)
Comment:
Chris
Summary:
This paper shows a framework for simultaneous grouping and recognition of shapes and symbols in free-form ink diagrams. Their approach is completely spatial, that not require any ordering on the strokes. There framework works as follows:
1. Build a proximity graph.Each node corresponds to stroke, and edges are added when strokes are in close to one another.
2. Search through this graph and find the optimal groupings. They use cost function to control to find the optimal groupings.They uses dynamic programming and A* algorithm to make search. In this paper, they focused on A* search. Each state in search space corresponds to cost value. Due to this brute force search, they propose two optimiaztion approaches.
1) grouping is valid only if its vertices are connected in the neighborhood graph.
2) Restrict the size of each subset V in the graph to be less than constant k, which can greatly decrease the time complexity.
3. For the recogniton of each part, they use the Adaboost classifier which can be automatically learned from the training dataset.
The result shows that their method gains about 97% accuracy for their testing data set.
Discussion :
Fairly good paper. Instead of seperating the steps of segmentation and classifying each part, they simultaneously find the optimal grouping as well as recognition They use fairly general method A* to search through all the search space, which has great time complexity. They use another fairly general optimization approaches to control this searching. Even though the accuracy the reported is very high, there are some problems here. The threshod to control the build of proximity graph can be set unappropriately so that can miss good important groupings, even they threshod values works very good, we cannot avoid some missing groupings in pratice.
Chris
Summary:
This paper shows a framework for simultaneous grouping and recognition of shapes and symbols in free-form ink diagrams. Their approach is completely spatial, that not require any ordering on the strokes. There framework works as follows:
1. Build a proximity graph.Each node corresponds to stroke, and edges are added when strokes are in close to one another.
2. Search through this graph and find the optimal groupings. They use cost function to control to find the optimal groupings.They uses dynamic programming and A* algorithm to make search. In this paper, they focused on A* search. Each state in search space corresponds to cost value. Due to this brute force search, they propose two optimiaztion approaches.
1) grouping is valid only if its vertices are connected in the neighborhood graph.
2) Restrict the size of each subset V in the graph to be less than constant k, which can greatly decrease the time complexity.
3. For the recogniton of each part, they use the Adaboost classifier which can be automatically learned from the training dataset.
The result shows that their method gains about 97% accuracy for their testing data set.
Discussion :
Fairly good paper. Instead of seperating the steps of segmentation and classifying each part, they simultaneously find the optimal grouping as well as recognition They use fairly general method A* to search through all the search space, which has great time complexity. They use another fairly general optimization approaches to control this searching. Even though the accuracy the reported is very high, there are some problems here. The threshod to control the build of proximity graph can be set unappropriately so that can miss good important groupings, even they threshod values works very good, we cannot avoid some missing groupings in pratice.
Reading #12. Constellation Models for Sketch Recognition. (Sharon)
Comment:
Chris
Summary:
This paper shows a system that adapts constelation or 'pictorial structur'model to the recognition of strokes in sketches of particular classes of objects. The model is designed to capture the structure of a particular class of object and is based on local features such as the shape or size of a stroke, and pairwise features, such as distance to other known parts. They uses the a probabilistic model from example sketches with know stroke labelings. The recogniton algorithm determines a maximum-likelihood labeling for an unlabelled sketch by serching through the space of possible label assignments using a multi-pss branch and bound algorithm. For searching, the current recognition process is largely top-down based
Discussion:
The paper seems interesting to me. Which is good paper for dealing with sketched picture. They use spatial information for recogniton, more specifically, use the spatial relathionship between each part. However, when then individual part is not correct, does the system can detect it?
Chris
Summary:
This paper shows a system that adapts constelation or 'pictorial structur'model to the recognition of strokes in sketches of particular classes of objects. The model is designed to capture the structure of a particular class of object and is based on local features such as the shape or size of a stroke, and pairwise features, such as distance to other known parts. They uses the a probabilistic model from example sketches with know stroke labelings. The recogniton algorithm determines a maximum-likelihood labeling for an unlabelled sketch by serching through the space of possible label assignments using a multi-pss branch and bound algorithm. For searching, the current recognition process is largely top-down based
Discussion:
The paper seems interesting to me. Which is good paper for dealing with sketched picture. They use spatial information for recogniton, more specifically, use the spatial relathionship between each part. However, when then individual part is not correct, does the system can detect it?
Reading #11. LADDER, a sketching language for user interface developers. (Hammond)
Comment:
Chris
Summary:
The paper introduce ladder!, which is my advisor's thesis work! cool.. The paper deals with syntactic pattern recognition. Ladder is description language for shapes. Ladder hierarchcaly define shapes from low level to higher level. The most two important components of ladder is component section and contratint section. Each shape consists of several primitive strokes and some constraints. The ladder detaily describe how each shape is built by other shapes as well as constraints. The ladder is very descriptive and is very useful for describe complex shapes. After providing shapes description to ladder, the system can automatically generate recognizer to recognize these shapes. The result shows that the system works well in flow chart diagram and UML diagram recognition. In fact, after building the ladder grammer for each shape, the remaining task for system is to parse the grammer, which can be accomplished by efficient compiler.
Discussion:
Very nice paper. Beautiful syntatic approach for sketch recogniton. It maximally release the designer's task. However, inevitably, there are some problems or this system. The most important one is speed!, parsing grammer is not easy task, which generally be accomplished by brute force search which is exponential for the given input size. Even though the ladder implements some optimazation techiqnues. the system can still suffer from slow speed problem. In fact, this is typical problem for syntatic recognition. It is not hard to describe shapes by using ladder, however, it is hard to recognize it if the strokes containing in shapes is too large.
Chris
Summary:
The paper introduce ladder!, which is my advisor's thesis work! cool.. The paper deals with syntactic pattern recognition. Ladder is description language for shapes. Ladder hierarchcaly define shapes from low level to higher level. The most two important components of ladder is component section and contratint section. Each shape consists of several primitive strokes and some constraints. The ladder detaily describe how each shape is built by other shapes as well as constraints. The ladder is very descriptive and is very useful for describe complex shapes. After providing shapes description to ladder, the system can automatically generate recognizer to recognize these shapes. The result shows that the system works well in flow chart diagram and UML diagram recognition. In fact, after building the ladder grammer for each shape, the remaining task for system is to parse the grammer, which can be accomplished by efficient compiler.
Discussion:
Very nice paper. Beautiful syntatic approach for sketch recogniton. It maximally release the designer's task. However, inevitably, there are some problems or this system. The most important one is speed!, parsing grammer is not easy task, which generally be accomplished by brute force search which is exponential for the given input size. Even though the ladder implements some optimazation techiqnues. the system can still suffer from slow speed problem. In fact, this is typical problem for syntatic recognition. It is not hard to describe shapes by using ladder, however, it is hard to recognize it if the strokes containing in shapes is too large.
Reading #10. Graphical Input Through Machine Recognition of Sketches (Herot) Task(s)
Comment:
Chris
Summary:
The paper introduces HUNCH system, a hierarchy of inference programs for sketch recognition,which is very old system. HUNCH works by taking input data and running several layers of inference programs on top of that data, from basic shapes to 3D interface. The system cannot work for certain users but not for other people, which seems user dependent. But
the point that hierarchically recognize the sketch is important as well as returning multiple interpretations.
Discussion:
Nice but old paper. It wrote in 1976 35years ago!! wow! All the techinques mentioned here is already exists today. But we must adimit that this is very nice work at that time. This paper just gives me brief knowledge of how the techniques evoles.
Chris
Summary:
The paper introduces HUNCH system, a hierarchy of inference programs for sketch recognition,which is very old system. HUNCH works by taking input data and running several layers of inference programs on top of that data, from basic shapes to 3D interface. The system cannot work for certain users but not for other people, which seems user dependent. But
the point that hierarchically recognize the sketch is important as well as returning multiple interpretations.
Discussion:
Nice but old paper. It wrote in 1976 35years ago!! wow! All the techinques mentioned here is already exists today. But we must adimit that this is very nice work at that time. This paper just gives me brief knowledge of how the techniques evoles.
Tuesday, November 23, 2010
Reading#18 Spatial Recognition and Grouping of Text and Graphics
Comment:
Chris
Summary:
In this paper, the author presents a framework for simultaneous grouping and recognition of shapes and symbols in free-form ink diagram. Their approach is completely spatial, and does not require any ordering on the strokes. Their implementation can be summarized as following.
1) Building building neighborhood graph. For graph (V,E), vertices are the individual stroks, and if two stroke are connected, then there will be edge between them. In order to determine if two strokes are connected, they use proximity distance measurement, they use threshold to control it. If distance between two stroks is less than the threshold, two vertices are connected.
2) The whole graph is divided into seperate subgraphs and each subgraph is recognized by recognizer. They will search through all these groupings and find optimal one. This is combinatorial problem which is computationaly very expensive. In this paper, they use some optimization techniques to decrease the complexity very much. There are two techniques used, the first one is they construct a neighborhood graph in which vertices that are colse to each other, the second one is to restrict the sizeof each subset to be less than a constant K. For searching, they used two approahces, dynamic programming and A* search. In this paper they mentioned the A* search approach.
3) The remaining thing is to build a recognizer, which is built using boosted decision trees. For avoiding overfitting, they used depth 3 decision trees.
Chris
Summary:
In this paper, the author presents a framework for simultaneous grouping and recognition of shapes and symbols in free-form ink diagram. Their approach is completely spatial, and does not require any ordering on the strokes. Their implementation can be summarized as following.
1) Building building neighborhood graph. For graph (V,E), vertices are the individual stroks, and if two stroke are connected, then there will be edge between them. In order to determine if two strokes are connected, they use proximity distance measurement, they use threshold to control it. If distance between two stroks is less than the threshold, two vertices are connected.
2) The whole graph is divided into seperate subgraphs and each subgraph is recognized by recognizer. They will search through all these groupings and find optimal one. This is combinatorial problem which is computationaly very expensive. In this paper, they use some optimization techniques to decrease the complexity very much. There are two techniques used, the first one is they construct a neighborhood graph in which vertices that are colse to each other, the second one is to restrict the sizeof each subset to be less than a constant K. For searching, they used two approahces, dynamic programming and A* search. In this paper they mentioned the A* search approach.
3) The remaining thing is to build a recognizer, which is built using boosted decision trees. For avoiding overfitting, they used depth 3 decision trees.
Sunday, November 21, 2010
Reading#15 An image-based, trainable symbol recognizer for hand-drawn sketches
Comment
Chris
Summary:
This papers deals with recognition problem using purely off-line approach, which consider each sketch or symbol as sets of pixels. The authors combined four different classifiers which are based on template matching. Most importantly, the author proposed one beautiful way of tacking orient invariant by transforming screen coordinate into polar coordinate. All the example templates are stored in the database, and each input symbol is matched with templates and return the top N best lists.
The four template matching metrics are Hausdorff distance, Modified Hausdoff distance, Tanimoto coefficient and Yule coefficient. The first two measure the dissimilarity which based on distance between two symbols, and the remaining two measure the similarity which based on the number of black pixels, number of white pixels and number of overlapping black or white pixels. After getting these four classifiers, they are normalized into [0,1] range and then combined for recognition.
The most important contribution of this paper is they proposed very smart way to tackle with orientation invariant. Because calculating the rotation angle in screen coordinate is computationally very expensive, they choose to first transform the symbol image into polar coordinates and mapped into [-pi, pi] range. In polar coordinate they can easily calculate the rotation angle and again transformed into screen coordinate to continue their recognition. Besides calculating rotation angle using polar coordinate, another one important usage of this coordinate is to prune template examples before getting into recognition step to decrease the time complexity. They reported that this method can eliminate about 90% template examples before applying classifiers.
The overall result seems very promising, in most of cases, they get more than 90% accuracy for top 1 returned result. And the users studies are based on graph symbols and digit symbols.
Discussion:
Another nice paper, purely off-line approach paper. There are several contribution of this paper. 1) Multi-classifier combination. 2) different distance matching approaches 3) Handling rotation using polar coordinate. 4) Decrease the impact of nearest points of centroid when transforming into polar coordinate. Paper very clearly shows the idea, and nicely organized. However, vision based recognition has difficulty of recognizing similar shapes, as mentioned by author. the future research might be combined vision-based approach with on-line stroke information.
Chris
Summary:
This papers deals with recognition problem using purely off-line approach, which consider each sketch or symbol as sets of pixels. The authors combined four different classifiers which are based on template matching. Most importantly, the author proposed one beautiful way of tacking orient invariant by transforming screen coordinate into polar coordinate. All the example templates are stored in the database, and each input symbol is matched with templates and return the top N best lists.
The four template matching metrics are Hausdorff distance, Modified Hausdoff distance, Tanimoto coefficient and Yule coefficient. The first two measure the dissimilarity which based on distance between two symbols, and the remaining two measure the similarity which based on the number of black pixels, number of white pixels and number of overlapping black or white pixels. After getting these four classifiers, they are normalized into [0,1] range and then combined for recognition.
The most important contribution of this paper is they proposed very smart way to tackle with orientation invariant. Because calculating the rotation angle in screen coordinate is computationally very expensive, they choose to first transform the symbol image into polar coordinates and mapped into [-pi, pi] range. In polar coordinate they can easily calculate the rotation angle and again transformed into screen coordinate to continue their recognition. Besides calculating rotation angle using polar coordinate, another one important usage of this coordinate is to prune template examples before getting into recognition step to decrease the time complexity. They reported that this method can eliminate about 90% template examples before applying classifiers.
The overall result seems very promising, in most of cases, they get more than 90% accuracy for top 1 returned result. And the users studies are based on graph symbols and digit symbols.
Discussion:
Another nice paper, purely off-line approach paper. There are several contribution of this paper. 1) Multi-classifier combination. 2) different distance matching approaches 3) Handling rotation using polar coordinate. 4) Decrease the impact of nearest points of centroid when transforming into polar coordinate. Paper very clearly shows the idea, and nicely organized. However, vision based recognition has difficulty of recognizing similar shapes, as mentioned by author. the future research might be combined vision-based approach with on-line stroke information.
Friday, November 19, 2010
Reading#17 Distinguishing Text From graphics in On-line Handwritten Ink
Comment:
Chris
Summary:
Another paper for shape vs text. But different from previous text vs shape papers we've read. The most important difference is that in this paper it actually utilize the context information. And finally they build HMM model for the sequence of all strokes. Besides individual stroke features, they use temporal information and gap information for sequence of strokes.
1. Independant stroke model. For each stroke, eleven-valued features are extracted. The process needs training samples. And for the testing phase, for given stroke s, they actually calcualte the probability of being text, can be described as P(TextStroke s). So, given input stroke, we can simply calcualte the probability by using trained model. Independant stroke model is only for each stroke, and in some case, it results in much error, so author proposed another improvement for this.
2. Hidden Markov model. The author also observe that probability of states transformation provides valuable information, which served as context information for given stroke sequence. In this case, there are two states, text and shape. And there are four transformation for these two states. Text to text, text to shape, shape to shape and shape to text. For the shape vs text problem, the problems is actually to assign state to each stroke. Thus, the problem can be easily modeld as Hidden markov process. The hidden layers obviously are the two states. and observation layers are the features we acutally calculate. So the problem changes to make the following formula have the maximum value.

However, P(XT) cannot be directly calculated from the models. So they used baysian rule to calculate it.
3. Bi-partite HMM In this step, they used the gap information between two strokes. In order to characterize the gap, they choose 5 features, and the training and mode process is similar as the first step for individual stroke model. After that, we simply incorporated this information into the HMM we got from step 2. The incorporation is very straighforward.
The result shows that their approach gains very good accuracy for shape vs text, especially the step 2 promote the accuracy very much although the step 3 does not impact the accuracy rate very much.
Disccussion:
What a great paper!!! i really like it and gives me so much valuable information!! First, it consider the context information for shape vs text task. this is greate improvement over the traditional method that only based on individual stroke features. Second, they build HMM model for the whole stroke sequence, which is purely probability approach and gives pretty good result. Third, it provides an easy way to add other context information into the HMM that already built. Besides, gap context information,we can futhur incoporate other context information very easily. The beautiful idea of this paper can be very useful for other research. Only one disadvantage that might have is people will not draw the text in natural order. Because HMM greatly depends on the temporal order, once people violate this order, the method might tends to get lower accuracy.
Chris
Summary:
Another paper for shape vs text. But different from previous text vs shape papers we've read. The most important difference is that in this paper it actually utilize the context information. And finally they build HMM model for the sequence of all strokes. Besides individual stroke features, they use temporal information and gap information for sequence of strokes.
1. Independant stroke model. For each stroke, eleven-valued features are extracted. The process needs training samples. And for the testing phase, for given stroke s, they actually calcualte the probability of being text, can be described as P(TextStroke s). So, given input stroke, we can simply calcualte the probability by using trained model. Independant stroke model is only for each stroke, and in some case, it results in much error, so author proposed another improvement for this.
2. Hidden Markov model. The author also observe that probability of states transformation provides valuable information, which served as context information for given stroke sequence. In this case, there are two states, text and shape. And there are four transformation for these two states. Text to text, text to shape, shape to shape and shape to text. For the shape vs text problem, the problems is actually to assign state to each stroke. Thus, the problem can be easily modeld as Hidden markov process. The hidden layers obviously are the two states. and observation layers are the features we acutally calculate. So the problem changes to make the following formula have the maximum value.

However, P(XT) cannot be directly calculated from the models. So they used baysian rule to calculate it.
3. Bi-partite HMM In this step, they used the gap information between two strokes. In order to characterize the gap, they choose 5 features, and the training and mode process is similar as the first step for individual stroke model. After that, we simply incorporated this information into the HMM we got from step 2. The incorporation is very straighforward.
The result shows that their approach gains very good accuracy for shape vs text, especially the step 2 promote the accuracy very much although the step 3 does not impact the accuracy rate very much.
Disccussion:
What a great paper!!! i really like it and gives me so much valuable information!! First, it consider the context information for shape vs text task. this is greate improvement over the traditional method that only based on individual stroke features. Second, they build HMM model for the whole stroke sequence, which is purely probability approach and gives pretty good result. Third, it provides an easy way to add other context information into the HMM that already built. Besides, gap context information,we can futhur incoporate other context information very easily. The beautiful idea of this paper can be very useful for other research. Only one disadvantage that might have is people will not draw the text in natural order. Because HMM greatly depends on the temporal order, once people violate this order, the method might tends to get lower accuracy.
Sunday, November 14, 2010
Reading#16 An Efficient Graph-Based Symbol Recognizer
Comment:
Chris
Summary:
This paper is completely different from what we read before. The paper deals with graph-based recognzier instead of using features to create recognizer. They represent each symbol as ARG(Attributed relational graph), each node is for primitive, each edge is for relationship between two primitive. Each node has two properties, primitive type and raletive length. Each edge has three properties, number of intersections, angle, position information, respectively. After convering each symbol into ARG, the remaining task is maching this ARG with best sample symbol. There are two steps. 1) Graph maching. Here, we find the each corresponding node between two graphs. This is well-known NP -complete problem. In this paper, author provides 4 different ways to approximate the best match. 2) Measureing maching score. author defines six different maching score metric in this paper as well as its weight value, which get from empirical study. System go through each sample and simply returns the best N-list. Result shows that about 93% of chance that the top 1 result is correctly returned.
Comments:
This paper shows another important area of pattern recognition. For graph-based approach there is one important issue we have to consider, which requires high computational cost, that is , graph matching or graph isomorphism, which remains NP-complete problem. But graph based approach has very good advantages while comparing to statistical or syntatic approach. The system does not depend on the drawn orientation and order, or scale(if use relative value), and can represent components' relationship and topology very accurately. The structural method is very appealing for me, and personaly perfer this structural approach to statistical method. Some papers also use structural way to recognize handwritting characters which seems harder than the work presented in this paper.
In all, this is pretty nice paper, and gives me very much information about modeling problem using structural way and use graph theory to solve it.
Chris
Summary:
This paper is completely different from what we read before. The paper deals with graph-based recognzier instead of using features to create recognizer. They represent each symbol as ARG(Attributed relational graph), each node is for primitive, each edge is for relationship between two primitive. Each node has two properties, primitive type and raletive length. Each edge has three properties, number of intersections, angle, position information, respectively. After convering each symbol into ARG, the remaining task is maching this ARG with best sample symbol. There are two steps. 1) Graph maching. Here, we find the each corresponding node between two graphs. This is well-known NP -complete problem. In this paper, author provides 4 different ways to approximate the best match. 2) Measureing maching score. author defines six different maching score metric in this paper as well as its weight value, which get from empirical study. System go through each sample and simply returns the best N-list. Result shows that about 93% of chance that the top 1 result is correctly returned.
Comments:
This paper shows another important area of pattern recognition. For graph-based approach there is one important issue we have to consider, which requires high computational cost, that is , graph matching or graph isomorphism, which remains NP-complete problem. But graph based approach has very good advantages while comparing to statistical or syntatic approach. The system does not depend on the drawn orientation and order, or scale(if use relative value), and can represent components' relationship and topology very accurately. The structural method is very appealing for me, and personaly perfer this structural approach to statistical method. Some papers also use structural way to recognize handwritting characters which seems harder than the work presented in this paper.
In all, this is pretty nice paper, and gives me very much information about modeling problem using structural way and use graph theory to solve it.
Reading #14Using Entropy to Distinguish Shape Versus Text in Hand-Drawn Diagrams (Bhat)
Comment:
Chris
Summary:
This is an another paper dealing with shape versus text. But it uses completely different method comparing to Reading#13. This paper only use entropy information to classify shape or text. In reading#13, the author use decision tree to find the most disdinguishable features and use these features to classify shape or text. However, in this paper, author use entropy measure, which represents uncertainty measurement, to classify shape or text. Paper shows that text is more randomly structured, which means has larger uncertainty rate than shape. Using this intution they create a code mapping model. They use angle between two consecutive points to represents the whole stroke, and these angles are put into seven different angle beams. Thus, after this processing, each stroke can be represented as sequence of characters -string. The next is to compute entropy value for this string, and they use this value to classify stroke as shape or text. For grouping strokes step, they simply use temporal information to group strokes. The result system shows good accuracy rate for shape vs text .
Discussion :
Smart intution & idea!! Idea is great, and very benificial for other applications. However.... I am wondering if it gets high accuracy in most of cases. This algorithms greatly depends on how the shape drawn, if the shape itself is very complex, and drawn cursively, the algorithms cannot classify it. And the grouping approach is not good.
The most ideal way to accomplish this task is , in my option, utilizing context information. Without the aid of context information, any recognition system cannot gain acceptable recognition rate.
Anyway, I have to say the idea is good, it is definitely a nice paper.
Chris
Summary:
This is an another paper dealing with shape versus text. But it uses completely different method comparing to Reading#13. This paper only use entropy information to classify shape or text. In reading#13, the author use decision tree to find the most disdinguishable features and use these features to classify shape or text. However, in this paper, author use entropy measure, which represents uncertainty measurement, to classify shape or text. Paper shows that text is more randomly structured, which means has larger uncertainty rate than shape. Using this intution they create a code mapping model. They use angle between two consecutive points to represents the whole stroke, and these angles are put into seven different angle beams. Thus, after this processing, each stroke can be represented as sequence of characters -string. The next is to compute entropy value for this string, and they use this value to classify stroke as shape or text. For grouping strokes step, they simply use temporal information to group strokes. The result system shows good accuracy rate for shape vs text .
Discussion :
Smart intution & idea!! Idea is great, and very benificial for other applications. However.... I am wondering if it gets high accuracy in most of cases. This algorithms greatly depends on how the shape drawn, if the shape itself is very complex, and drawn cursively, the algorithms cannot classify it. And the grouping approach is not good.
The most ideal way to accomplish this task is , in my option, utilizing context information. Without the aid of context information, any recognition system cannot gain acceptable recognition rate.
Anyway, I have to say the idea is good, it is definitely a nice paper.
Monday, October 18, 2010
Reading #13 Ink Features for Diagram Recognition
Comment:
Chris
Summary:
This paper tried to solve very important problem in Sketch recognition : Distinguish text and shape. Acutally, most of document of sketched diagram consists of text and shape or drawing diagram. However, recognzing text and shape are two independant tasks that we need to reocognize seperately. So the first task is to find which part is text and which part is shape. In fact, this is very difficult problem and there is no universal solution for this problem. In this paper, the author shows very intuitive way to distinguish these two and gains reasonable accuracy but still not very high. The overall approach is very simple, is to find most disdinguishable features for differenciating shape and text. The author initially choose forty-six features, and use decision tree to find the most important features . The final feature set consists of eight most disdinguishing features. In the result part of this paper, the author compares his recognizer with Microsoft divider and Inkkit, and found that accuracy is much higher than these two.
Discussion:
For me, this paper is very informative from the perspective of choosing features. For different sketching system, we need to recognize different sybmols. For statistical pattern recognition, the most important task is to find most disdinguishing feature set. Using too few feature may result in low accuracy of sytem, choosing too many features instead results in overfitting. This paper gives me answer, approach used in this paper is a really nice way to find good features among all the candidate features. We can make automatic feature extraction system for certain domain using decision tree like in this paper.
Chris
Summary:
This paper tried to solve very important problem in Sketch recognition : Distinguish text and shape. Acutally, most of document of sketched diagram consists of text and shape or drawing diagram. However, recognzing text and shape are two independant tasks that we need to reocognize seperately. So the first task is to find which part is text and which part is shape. In fact, this is very difficult problem and there is no universal solution for this problem. In this paper, the author shows very intuitive way to distinguish these two and gains reasonable accuracy but still not very high. The overall approach is very simple, is to find most disdinguishable features for differenciating shape and text. The author initially choose forty-six features, and use decision tree to find the most important features . The final feature set consists of eight most disdinguishing features. In the result part of this paper, the author compares his recognizer with Microsoft divider and Inkkit, and found that accuracy is much higher than these two.
Discussion:
For me, this paper is very informative from the perspective of choosing features. For different sketching system, we need to recognize different sybmols. For statistical pattern recognition, the most important task is to find most disdinguishing feature set. Using too few feature may result in low accuracy of sytem, choosing too many features instead results in overfitting. This paper gives me answer, approach used in this paper is a really nice way to find good features among all the candidate features. We can make automatic feature extraction system for certain domain using decision tree like in this paper.
Reading #9 PaleoSketch: Accurate Primitive sketch Recognition and Beautification
Comment:
Chris
Summary:
Paleosketch is the primitive sketch recognition library, which is widely used in many projects. In fact, for sketch recognition, the first very begining task is to recognize primities as line, polyline, arc, and etc. For most of sketching system, the first step is to recognize each stroke as primitives, then hierarchyly builds more complex system by using botton-up approach. Thus, the primitive recognition the most important steps for sketch recognition, and greatly affect the later processing and recognition and overall accuracy of sketching system. Paleosketch is an accurate, configurable primitive recognition library, that can recognize each stroke as eight different primitives, line, polyline, circle, ellipse,arc curve,spiral and helix. PaleoSketch starts by preprocessing step that remove noise of strokes. In the implementation part, the author shows most disdingushiable features for each primitve recognition. Author shows that two most importatn contributuion of this paper is to use two new important features, NDDE and DCR respectively. These two features are very useful for differenciate polyline and curve. Anther important contribution of this paper is new ranking algorithm as mentioned in this paper. In the remaining part of paper, the author compares different versions of PaleoSketch as well as with SSD, the result shows that Paleo has very good recognition accuracy.
Discussion:
PaleoSketch is accurate and an important contribution to the Sketch Recognition community. It uses very good features to recognize differrent primitives. We can easily configure PaleoSketch based on our own needs and requriement of specific system. However, in my opition, it stills needs improvement. It acctually uses fixed threshold for all the features. This cause one problem, for recognizing Polyline, if part of these lines are not passed polyline test, it will failed and instead it is likely to recognize it as circle. Thus, my idea is instead of using fixed threshold for each part, we can make it flexible by using interval threshold. when we recognize certain stroke, we can calculate the sum of each part of values and then use the some distribution of this sum value. In this case, we can solve this problem : Certain part of stroke failed to pass the test, but from overall perspective, the whole part can still pass the test.
Chris
Summary:
Paleosketch is the primitive sketch recognition library, which is widely used in many projects. In fact, for sketch recognition, the first very begining task is to recognize primities as line, polyline, arc, and etc. For most of sketching system, the first step is to recognize each stroke as primitives, then hierarchyly builds more complex system by using botton-up approach. Thus, the primitive recognition the most important steps for sketch recognition, and greatly affect the later processing and recognition and overall accuracy of sketching system. Paleosketch is an accurate, configurable primitive recognition library, that can recognize each stroke as eight different primitives, line, polyline, circle, ellipse,arc curve,spiral and helix. PaleoSketch starts by preprocessing step that remove noise of strokes. In the implementation part, the author shows most disdingushiable features for each primitve recognition. Author shows that two most importatn contributuion of this paper is to use two new important features, NDDE and DCR respectively. These two features are very useful for differenciate polyline and curve. Anther important contribution of this paper is new ranking algorithm as mentioned in this paper. In the remaining part of paper, the author compares different versions of PaleoSketch as well as with SSD, the result shows that Paleo has very good recognition accuracy.
Discussion:
PaleoSketch is accurate and an important contribution to the Sketch Recognition community. It uses very good features to recognize differrent primitives. We can easily configure PaleoSketch based on our own needs and requriement of specific system. However, in my opition, it stills needs improvement. It acctually uses fixed threshold for all the features. This cause one problem, for recognizing Polyline, if part of these lines are not passed polyline test, it will failed and instead it is likely to recognize it as circle. Thus, my idea is instead of using fixed threshold for each part, we can make it flexible by using interval threshold. when we recognize certain stroke, we can calculate the sum of each part of values and then use the some distribution of this sum value. In this case, we can solve this problem : Certain part of stroke failed to pass the test, but from overall perspective, the whole part can still pass the test.
Reading #8 A Lightweight Multistroke Recognizer for User Interface Prototypes
Comment:
Chris
Summary:
This paper is extention of previous 1$ recognizer. As same as 1$ recognizer, the purpose of this recognizer is not provide systematic and complex recognizer, instead it provides fast implementation, keep its simplicity. It mostly based on 1$ recognizer, but it makes great improvement that can recognizer multstroke symbols which is the limiatio of 1$ recognizer. Like 1$ recognizer, it consists of several steps. but the preprocessing steps is different from 1$ recognizer. For N$ recognzier, for each template symbol, it generates all the permutations of stroke combination, and the connect end points of consecutive strokes to make it unistroke. Aftet that, we can treat is unistroke just like in 1$ recognzier. Due to the computation explosion, the author gives some heuristic approach the prume some comparing templates. The author use start angle of stroke to eliminate unlikely matched candiate symbols. Instead of decreasing the accuracy of recognition, the author said this appraoch improve the recognizer accuracy. Another heuristic is to use number of strokes information, which futhur decrease the compuation cost. For the result part, the author said N$ recognizer gains about 96%, 97% accuracy rate.
Discussion:
Nice, simple, easy to understand approach to recognizer multistrokes. I pretty much like the idea of this paper. We can easily intergrate into our own system. However, as the author says, easy means there is limitation. For the large set of symbols, this approach is obvioulsy undergo high computation cost, which is also the limitation of template matching approach. There are might some improvements for N$ recognzier. 1. Intead of permuting all kinds of multistrokes, we can use certain more informative combination. 2. For the large symbol set. we can build binary tree to store these training data to improve the efficiency, clearly, we have to use some geometric features in that case to dinguish symbols.
Chris
Summary:
This paper is extention of previous 1$ recognizer. As same as 1$ recognizer, the purpose of this recognizer is not provide systematic and complex recognizer, instead it provides fast implementation, keep its simplicity. It mostly based on 1$ recognizer, but it makes great improvement that can recognizer multstroke symbols which is the limiatio of 1$ recognizer. Like 1$ recognizer, it consists of several steps. but the preprocessing steps is different from 1$ recognizer. For N$ recognzier, for each template symbol, it generates all the permutations of stroke combination, and the connect end points of consecutive strokes to make it unistroke. Aftet that, we can treat is unistroke just like in 1$ recognzier. Due to the computation explosion, the author gives some heuristic approach the prume some comparing templates. The author use start angle of stroke to eliminate unlikely matched candiate symbols. Instead of decreasing the accuracy of recognition, the author said this appraoch improve the recognizer accuracy. Another heuristic is to use number of strokes information, which futhur decrease the compuation cost. For the result part, the author said N$ recognizer gains about 96%, 97% accuracy rate.
Discussion:
Nice, simple, easy to understand approach to recognizer multistrokes. I pretty much like the idea of this paper. We can easily intergrate into our own system. However, as the author says, easy means there is limitation. For the large set of symbols, this approach is obvioulsy undergo high computation cost, which is also the limitation of template matching approach. There are might some improvements for N$ recognzier. 1. Intead of permuting all kinds of multistrokes, we can use certain more informative combination. 2. For the large symbol set. we can build binary tree to store these training data to improve the efficiency, clearly, we have to use some geometric features in that case to dinguish symbols.
Reading #7 Sketch Based Interfaces:Early Processing for Sketch Understanding
Comment:
Chris
Summary:
In this paper, the author focused on preprocessing steps for sketch recognition, especially for corner finding in stroke, fitting lines and curves. Generally, the early prorecessing consists of three phases, approximation, beautification and basic recognition, respectively. The most appealing part of this paper is the part of explanation of finding corners. The author uses two kinds of graph, Curvature graph and speed graph. From careful examination, author found that people tends to slow down at each corner of the stroke, which is a very intuitive idea. The author also found that using curvature graph only or speed graph only cannot find all the corners very effectively, this is the reason why author combined these two graphs to detect vertices, which gives good results. In the remaining part of paper, the author also shows the approach of how to handling curves as well as fitting problem.
Discussion:
Paper is excellent. I am very into the first part of paper that find the corners. I like the idea of using speed graph, it is really interesting and intuitive for me. Even though in some cases, this does not gives good result, generally, it is true that people tends to draw slowly at each corner of stroke. Thus, speed graph, definitely is good, then how about the acceleration graph, which is the deriative of speedy graph. I think we can also use acceleration graph for this purpose.. furthermore, derivative of accelaration graph, I am not sure if it useful or not, however, we could try.
Chris
Summary:
In this paper, the author focused on preprocessing steps for sketch recognition, especially for corner finding in stroke, fitting lines and curves. Generally, the early prorecessing consists of three phases, approximation, beautification and basic recognition, respectively. The most appealing part of this paper is the part of explanation of finding corners. The author uses two kinds of graph, Curvature graph and speed graph. From careful examination, author found that people tends to slow down at each corner of the stroke, which is a very intuitive idea. The author also found that using curvature graph only or speed graph only cannot find all the corners very effectively, this is the reason why author combined these two graphs to detect vertices, which gives good results. In the remaining part of paper, the author also shows the approach of how to handling curves as well as fitting problem.
Discussion:
Paper is excellent. I am very into the first part of paper that find the corners. I like the idea of using speed graph, it is really interesting and intuitive for me. Even though in some cases, this does not gives good result, generally, it is true that people tends to draw slowly at each corner of stroke. Thus, speed graph, definitely is good, then how about the acceleration graph, which is the deriative of speedy graph. I think we can also use acceleration graph for this purpose.. furthermore, derivative of accelaration graph, I am not sure if it useful or not, however, we could try.
Sunday, September 5, 2010
Reading #6: Protractor: A Fast and Accurate Gesture Recognizer (Li)
{kind=link}
Comment :
Chris Aikens
Summary:
This paper introduce anther light-weighted single gesture recognizer, Protractor, which is very easy to implement and incorporated into any application system as well as mobile devices due to its simplicity and efficiency. Li, who is the designer of 1$ recognizer, developes Protractor based on his past work for 1$ recognizer. These two recognizers are both featured as super simplicty, they are similar in many aspects, however, Protractor is much more efficent than 1$ recognizer because it uses cosine similarity instead of distance measure which used in 1$ recognzier.
For implementation detail, they used similar preprocessing steps, except for calculating rotation angle and they uses different scaling mechanisim (1$ uses rescaling to fix a square while Protractor does not use rescaling)
Next, the most different part is , to calculate the optimal angular distance. Protractor stores stroke points as vector, then try to calculate the cosine similartiy between template vector and new stroke vector. Because indicative value is only an approximation measure of a gesture's orientation, Protractor should futhur rotate template gesture to get the best angle, which makes two vectors has largest similarty. In order to find such optimal angle, Li first shows us the formula which looks like :

In order to make left part of formula makes minimum, we only need to calcualte angle theta which makes its derivative function equals to 0. Li also shows us the final calculation result. By doing in this way, computation cost is significantly decreased, He no longer need to use iterative way to find such optimum value which is time consuming.
In the evaluation part, he compared Protractor with 1$ recognizer in terms of accuracy and efficiency. He found that Protracor actually outperformed its peer in many aspects including 1$ recognizer.
The following table shows the comparison between Protractor and 1$ recognizer.
| 1$ Recognizer | Protractor | |
|---|---|---|
| Preprocessing |
|
|
| Classification |
|
|
| Accuracy |
|
|
| Time cost | MUCH slower than Protractor, time grows fast as the number of training samples grows | MUCH faster than 1$ recognizer, time grows much slower than 1$ recognizer |
Discussion :
This paper is an improvement of Li's last paper, 1$ recognizer. In this paper, he uses different similarity measure metric which is much faster than 1$ recognizer. He noticed that when he implements 1$ recognizer it uses iterative computation for calculating optimal angle which is time consuming. In this paper, he improves this part by using vector respentation instead of pure 2D representation of strokes as in 1$ recognizer. Due to the fast computation, it becomes feasible to apply to much larger gesture set. I like the smart idea behind computing optimal angle by using mathematical equaiton.
Reading #5: Gestures without Libraries, Toolkits or Training: A $1 Recognizer for User Interface Prototypes (Wobbrock)
Comment :
Sam
Summary :
This paper introduces the 1$ recognizer developed by Dr.Wobbrock. 1$ recognizer is so simple that can be integrated into any system without any trouble and only requires hundreds lines of code, which is the major feature of 1$ recognizer. 1$ recognizer only handles single stroke, and new stroke class can be easily added to the exsting stroke set. It does not use complicated algorithms like training, but template maching is used which means no training is required. It use the distance measure to calcualte similarity of two strokes. It is very easy to understand and easy to impelement, that's why 1$ recognizer can be used even without any prior knowledge about AI and gesture recognition.
There are four steps for recognizing; Resample, Rotate, Scale and Translate, Find the optimal angle and best scores, respectively. For resample, he uses fixed number of points per stroke, and distance between each neighboring points are equal. For Rotate, he used "Indicative angle", which formed between centroid of gesture and gesutre's first point. This step can eliminate angle variance. For scale and translate step, he made the stroke as fixed size bounded by a fixed lengh of squre, then moves the gesture to the reference point so that the centroid will be (0,0) after translating. After the first three steps,we still does not guarantee that two strokes are both at best angle when comparing these two strokes. Thus, in this step, he furthur calculates the best angle, which makes the distance between given two strokes is minimum. Finally, the minumum distance among all the comparision is selected, then output the class label.
1$ recognizer : http://depts.washington.edu/aimgroup/proj/dollar/
N$ recognizer: http://faculty.washington.edu/wobbrock/pubs/gi-10.2.pdf
Discussion :
1$ recognizer is so simple that can be integrated into any system, despite of its simplicity, the accuracy is very high. However, there are some drawbacks of 1$ recognizer.
Sam
Summary :
This paper introduces the 1$ recognizer developed by Dr.Wobbrock. 1$ recognizer is so simple that can be integrated into any system without any trouble and only requires hundreds lines of code, which is the major feature of 1$ recognizer. 1$ recognizer only handles single stroke, and new stroke class can be easily added to the exsting stroke set. It does not use complicated algorithms like training, but template maching is used which means no training is required. It use the distance measure to calcualte similarity of two strokes. It is very easy to understand and easy to impelement, that's why 1$ recognizer can be used even without any prior knowledge about AI and gesture recognition.
There are four steps for recognizing; Resample, Rotate, Scale and Translate, Find the optimal angle and best scores, respectively. For resample, he uses fixed number of points per stroke, and distance between each neighboring points are equal. For Rotate, he used "Indicative angle", which formed between centroid of gesture and gesutre's first point. This step can eliminate angle variance. For scale and translate step, he made the stroke as fixed size bounded by a fixed lengh of squre, then moves the gesture to the reference point so that the centroid will be (0,0) after translating. After the first three steps,we still does not guarantee that two strokes are both at best angle when comparing these two strokes. Thus, in this step, he furthur calculates the best angle, which makes the distance between given two strokes is minimum. Finally, the minumum distance among all the comparision is selected, then output the class label.
1$ recognizer : http://depts.washington.edu/aimgroup/proj/dollar/
N$ recognizer: http://faculty.washington.edu/wobbrock/pubs/gi-10.2.pdf
Discussion :
1$ recognizer is so simple that can be integrated into any system, despite of its simplicity, the accuracy is very high. However, there are some drawbacks of 1$ recognizer.
- Low Efficiency, template maching is time consuming, especailly when there are many gesture classes and many sample gestures per class, 1$ recognizer will become unfeasible to use in that situation. No training required, but recognizing process costs too much time.
- Only handle single stroke. There are ways can improve 1$ recognizer to handle multstrokes. But it needs some trickes to do that, because when we use template matching, the number of sample gestures will be exponentially grow as the number of stroke per gesture grows.
Reading #4: Sutherland. Sketchpad: A Man-Made Graphical Communication System (Sutherland)
Comment :
Hong-Hoe(Ayden)-Kim
Summary :
This paper introduces the first pen-based input system, SketchPad, which began in 1964, was the seminal work of Ivan Sutherland, who recevied Turing Award later in 1988 for this system. He started by illustraiting how to draw Haxagonal lattice (Figure 1) using SketchPad.

He first created SIX-SIDED figure and one CIRCLE and then applied several operations like "Move","Delete" to get HAXAGON which makes "Subpicture", and, actually the Haxagonal Lattice consists of large number of the same HAXAGON. Thus, once the HAXAGON is created, then the system can easily generate the Haxagonal lattice, author also said that handling this kind of repetitive work was the most important feature of SketchPad system. Along with this example, some capabilities of system were mentioned, Subpicture, constraint and Definition copying.
In the remaining part of paper, author shows the design details of the system, more specifically,
Hong-Hoe(Ayden)-Kim
Summary :
This paper introduces the first pen-based input system, SketchPad, which began in 1964, was the seminal work of Ivan Sutherland, who recevied Turing Award later in 1988 for this system. He started by illustraiting how to draw Haxagonal lattice (Figure 1) using SketchPad.
{kind=link}
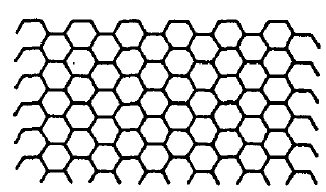
He first created SIX-SIDED figure and one CIRCLE and then applied several operations like "Move","Delete" to get HAXAGON which makes "Subpicture", and, actually the Haxagonal Lattice consists of large number of the same HAXAGON. Thus, once the HAXAGON is created, then the system can easily generate the Haxagonal lattice, author also said that handling this kind of repetitive work was the most important feature of SketchPad system. Along with this example, some capabilities of system were mentioned, Subpicture, constraint and Definition copying.
In the remaining part of paper, author shows the design details of the system, more specifically,
- Ring Structure and its basic operations including insert, delete, copy..etc.
- Strcutre of Sketchpad system, which was the typical object oriented system.
- Introuducing LIGHT PEN
- Introuducing the displaying system, such as how to magnify the picture, how to display line, circle,digit,text,etc.
- How to use recursive functions to manipulate operations, functions such as Recursive deleting , recursive merging and recursive display, as well as how to copy the drawings.
- Constraint satisfaction, can use swtich to turn on or off this feature, most importantly, it can distinguish Sketchpad drawing from a traditional drawing. By using this feature, computer can understand the people's intention. So, even people makes mistakes when drawing picutres, computer can correct and beautify them once people set this contratint to the computer.
(Following demo videos of SketchPad system shows us how it was working)
1. Brief overview of SketchPad System
2. SketchPad Demo Part(1/2)
3. SketchPad Demo Part(2/2)
Discussion :
What was an excellent system that made even 50 years ago! There is no doubt that how this work greatly impacted later HCI field and thousdans of researchers. Today, pen-based devices are becoming more and more popular and makes them easy for people to use. When compared with today's system, SketchPad is nothing more than a drawing pad. People have to use Buttons and knobs to control the drawing, which seems very unefficient and too complicated to use. But anyway, it is the milestone of today's HCI, we can see the revolutionary process of new technology from this work.
Reading #3: “Those Look Similar!” Issues in Automating Gesture Design Advice (Long)
Comment:
Summary :
This paper introduces an interface design tool, quill, that uses unsolicited advice to help designers to design gestures. Authors notice that it is difficult to design gestures that will be recognized well by the computer due to the similarity of different gestures. In order to handle this problem, they developed quill, to analyze the gestures, find similar gestures and warn designers by showing messages and tell them how to fix the gesture. When training quill, Rubine’s training algorithm was used, and for each type of gesture, ten to fifteen examples were drawn.
In the remaining parts of paper, author shows some challenges about designing this system. When giving advice to designers, there will be some considerations such as advice timing, how much advice to display and advice content. They analyze the designers’ common habits and shows detailed information for how to design system to make is more friendly for designers to use. They also examined long-running operations and gives some optional choices for executing these operations but not make designers confused about it.
Discussion:
Saturday, September 4, 2010
Reading #2: Specifying Gestures by Example (Rubine)
Comment :
Summary :
In this paper, Dean Rubine introduce his program GRANDMA and describe his single-stroke gesture recognizer which used linear classifier to recognize new single stroke.
In this paper, he describe 13 features he used to train recognizer, some of which are still widely used today. For machine learning algorithm, he used linear classifier, which is rather simple and easy to implement. Training process calculates the weight value for each feature for each class label. In the evaluation part, he shows that his recognizer has high accuracy. He also shows one very important fact that when training the recognizer, 15 examples per class is enough. Besides this, anther contribution of this paper was that he described rejection method for some ambiguous situation.
Discussion :
This paper plays very important role in sketch recognition field, and it tells the basic idea of building real time recognizer. Even though recognizer only handle single stroke, this work can be extended to build multi-stroke recognizer, which is very active field today. In fact, in real world, most of sketches are multi-strokes. We cannot put restriction that user only use single stroke to draw diagram or write characters. For extension part, Rubine briefly introduce two important things: Eager Recognition and Multi-finger recognition. For eager recognition, he said system can recognize while user was making it, this idea is very important for build real time system, but it must be able to give feedback and continually check and modify the recognition result by utilizing context information to maximize the overall confidence. I am pretty interest about multi-finger recognition, which is the most important feature of Apple product. I am also surprised about that this idea actually comes from decades ago. Perhaps in the near future, we don't need keyboard, mouse, what we only need are our fingers and mouth, which are enough to fully control computer and other electronic devices.
by Li 09/04/2010
Wednesday, September 1, 2010
Reading#1 Gesture Recognition BY Hammond
Commented on :
Sam
Summary :
This survey chapter gives us brief overview of what is gesture recogntion and how to write a simple gesture recognizer by Introducing Rubine,Long and 1$ recognizer. Although these recognizers are very simple and easy to implement, this chapter clearly shows us the basic idea of sketch recognition, which still is the main idea of implementing much more complicated things.
For these three recognizers, the first two use classifer to recognizer gesture while 1$ recognizer use template matching technique to classify gesture. Rubine provided 13 features which still beging widely used today. For the extension of the these 13 features, long provides 22 features to slightly improve the acuracy. After calculating all the features for given stroke, they use linear classifer to recognize this stroke. ( the major part of training is to calcualte the weight value for each feature i of each class label c, noted as Wci, then used linear combination of these weight values to calculate the labe c which makes the confidence value maximum)
For 1$ recognizer, it used template matching technique. It calcualtes the distance between new gesture and every sample gesture stored in database, finally the least pair will be returend. In 1$ recognizer, it uses indicative angle value to handle the rotation problem. 1$ recognizer is so simple that can be embedded in any application easily which is the main advantages of this recognizer.
Discussion :
1. Rubine recognizer has good recognition rate, Long extends the feature set and makes it contain 22 features. However, most of features actually derives from the Rubine features, I am still wondering whether it really improves the accuracy ? More features also means more computation, and accuracy does not increase as the the number of features increase, what we should do is to find the features mostly distinguish different class symbols..
2. Template Matching technique has very high accuracy, it is true. But the most important problem is computation costs. Thus, for 1$ recognizer, the number of symbol class should be small, and we should provide limited number of samples gestures. Obviously 1$ recognizer can not apply to large system, but the idea is excellent. However I prefer to use linear or non-linear classier first to get the top N list and then use template matching algorithms which might be fast and gain higher accuracy... ?? 1$ recognizer use fixed length and width to preprocessing the stroke, however, we might use fixed length while makes width flexible to keep the ratio unchanged.
3. These three recognizers can only applied to unistroke. If we write one symbol as multistrokes, it becomes impossible to recognize it. Especially when we want to use template matching for multistrokes, time complexity will become exponential to the number of strokes.
4. How do you think of if we use the same feature set but different machine learning algorithms?
For example, we just assume using Rubine Features, and we can choose any algorithm from linear classifier, ANN, HMM, DT, SVM, Boosting..etc. We might try to guess what result we can get. Does the algorithm we choose strongly related to the recognition accuracy.. ?
Sam
Summary :
This survey chapter gives us brief overview of what is gesture recogntion and how to write a simple gesture recognizer by Introducing Rubine,Long and 1$ recognizer. Although these recognizers are very simple and easy to implement, this chapter clearly shows us the basic idea of sketch recognition, which still is the main idea of implementing much more complicated things.
For these three recognizers, the first two use classifer to recognizer gesture while 1$ recognizer use template matching technique to classify gesture. Rubine provided 13 features which still beging widely used today. For the extension of the these 13 features, long provides 22 features to slightly improve the acuracy. After calculating all the features for given stroke, they use linear classifer to recognize this stroke. ( the major part of training is to calcualte the weight value for each feature i of each class label c, noted as Wci, then used linear combination of these weight values to calculate the labe c which makes the confidence value maximum)
For 1$ recognizer, it used template matching technique. It calcualtes the distance between new gesture and every sample gesture stored in database, finally the least pair will be returend. In 1$ recognizer, it uses indicative angle value to handle the rotation problem. 1$ recognizer is so simple that can be embedded in any application easily which is the main advantages of this recognizer.
Discussion :
1. Rubine recognizer has good recognition rate, Long extends the feature set and makes it contain 22 features. However, most of features actually derives from the Rubine features, I am still wondering whether it really improves the accuracy ? More features also means more computation, and accuracy does not increase as the the number of features increase, what we should do is to find the features mostly distinguish different class symbols..
2. Template Matching technique has very high accuracy, it is true. But the most important problem is computation costs. Thus, for 1$ recognizer, the number of symbol class should be small, and we should provide limited number of samples gestures. Obviously 1$ recognizer can not apply to large system, but the idea is excellent. However I prefer to use linear or non-linear classier first to get the top N list and then use template matching algorithms which might be fast and gain higher accuracy... ?? 1$ recognizer use fixed length and width to preprocessing the stroke, however, we might use fixed length while makes width flexible to keep the ratio unchanged.
3. These three recognizers can only applied to unistroke. If we write one symbol as multistrokes, it becomes impossible to recognize it. Especially when we want to use template matching for multistrokes, time complexity will become exponential to the number of strokes.
4. How do you think of if we use the same feature set but different machine learning algorithms?
For example, we just assume using Rubine Features, and we can choose any algorithm from linear classifier, ANN, HMM, DT, SVM, Boosting..etc. We might try to guess what result we can get. Does the algorithm we choose strongly related to the recognition accuracy.. ?
My First Post

1. Photo
2. Email Address : nadalwz1115@hotmail.com or liwenzhe@tamu.edu
3. Graduate standing: 2nd year MS
4. Why are you taking this class?
Handwritting is very exciting area for me, and this is related to my thesis.
5. What experience do you bring to this class?
Interest & some knowledge about sketch recognition AND AI
6. What do you expect to be doing in 10 years?
Be an expert in computer technology, also I am quite interested in economics area , so I will try to figure out what kinds of computer skill that I can bring into these fields.
7. What do you think will be the next biggest technological advancement in computer science?
AI makes computer more intelligent, but anyway, I always believe that can not replace human brain
HCI makes computer much easier to use. Handwritting and Speech are the most areas that make this become true. Future computer will be smart enough that can talk with people, play with children.. Portal device will have full functionality that today's computer has.
8. What was your favorite course when you were an undergraduate (computer science or otherwise)?
OS, Data structure and Algorithms, etc.
9. What is your favorite movie and why?
Favorite movie?? hmm..... "Avatar", first 3D Movie I watched .
10. If you could travel back in time, who would you like to meet and why?
Robin Li, I would choose to be classmate with him.
11. Give some interesting fact about yourself.
I really like sports.. football/basketball/tenis/swimming/pingpong/skate/running......
Subscribe to:
Posts (Atom)